Unlocking SAP BusinessObjects Data: A Comprehensive Guide to Retrieving Documents with Python
Introduction
In the realm of business intelligence and data analytics, SAP BusinessObjects stands tall as a powerful tool, empowering organizations to transform raw data into actionable insights. While its capabilities are robust, accessing and managing data programmatically can offer even greater flexibility. This blog post delves into the world of SAP BusinessObjects and Python, demonstrating a step-by-step approach to retrieve the list of documents effortlessly.
Why This Matters
In SAP BusinessObjects, years of operation can result in a cluttered mess of documents and folders. Cleaning up this chaos is crucial for data teams. By using Python to retrieve the details like path and last modified date and status for all documents, you gain a powerful tool.
Python Solution
Part 1: Authentication
To initiate the authentication process, please replace the placeholder values for “username,” “password,” and “localhost” with your specific configuration details.
import requests
import pandas as pdp
import xml.etree.ElementTree as ET
# define the login request parameters
username = 'username'
password = 'password'
localhost = 'localhost'
auth_type = 'secEnterprise'
login_url = 'http://{}:6405/biprws/logon/long'.format(localhost)
login_data = f'<attrs xmlns="<http://www.sap.com/rws/bip>"><attr name="userName" type="string">{username}</attr><attr name="password" type="string">{password}</attr><attr name="auth" type="string" possibilities="secEnterprise,secLDAP,secWinAD,secSAPR3">{auth_type}</attr></attrs>'
login_headers = {'Content-Type': 'application/xml'}
# send the login request and retrieve the response
login_response = requests.post(login_url, headers=login_headers, data=login_data)
# parse the XML response and retrieve the logonToken
root = ET.fromstring(login_response.text)
logon_token = root.find('.//{<http://www.sap.com/rws/bip>}attr[@name="logonToken"]').text
api_headers = {'Content-Type': 'application/xml', 'X-SAP-LogonToken': logon_tokenThe code focuses on the initial authentication process, forming a secure connection to the server. User credentials, server details, and authentication type are configured, and a POST request is made to the specified login URL. The XML response from the server is parsed to extract the crucial logonToken. This token is then employed to construct headers for subsequent API requests, ensuring authenticated access to SAP BusinessObjects.
Part 2: Data Retrieval and DataFrame Creation
Previewing Retrieved Data: First Document’s Name
As we venture into data retrieval from SAP BusinessObjects, a peek at the obtained information reveals its structure. This Python snippet fetchs all the information about documents from the server. If you run the code, it will print the name of the first document.
url = "http://{}:6405/biprws/raylight/v1/documents/".format(localhost)
response = requests.get(url,api_headers)
root = ET.fromstring(response.text)
first_docu_key = root.findall('document')[0][2].tag
first_docu_item = root.findall('document')[0][2].text
print(first_docu_key, ":", first_docu_item)Data Transformation Functions: Transform to DataFrame
The Python functions, get_dataframe_from_response and get_all_dataframe, work together to simplify SAP BusinessObjects data retrieval. The first function transforms XML data into a structured pandas DataFrame, capturing document attributes. The second function efficiently handles scenarios with documents exceeding a single request's limit by appending multiple DataFrames. Collectively, these functions streamline the conversion of XML to DataFrame and provide an easy solution for handling a large number of documents.
def get_dataframe_from_response(response):
# Parse the XML data
root = ET.fromstring(response.text)
# Extract the data into a list of dictionaries
res = []
for item in root.findall('document'):
doc_dict = {}
for elem in item.iter():
if elem.text is not None:
doc_dict[elem.tag] = elem.text
res.append(doc_dict)
# Convert the list of dictionaries to a pandas dataframe
df = pd.DataFrame(res)
return df
def get_all_dataframe(url):
documents = []
for i in range(50):
offset = i * 50
url_offset = url + "?offset={}&limit=50".format(offset)
response = requests.get(url_offset, headers=api_headers)
df = get_dataframe_from_response(response=response)
if df.empty:
break
else:
documents.append(df)
dataframe = pd.concat(documents, axis=0)
return dataframeRetrieve detailed information about SAP BusinessObjects documents effortlessly using a single line of Python code. Utilize the get_all_dataframe function, and the resulting df_documents DataFrame provides a straightforward overview of document attributes.
url = "http://{}:6405/biprws/raylight/v1/documents/".format(localhost)
df_documents = get_all_dataframe(url=url)
print(df_documents.head())Showcasing df_documents: What follows is a glimpse into the dataframe structure
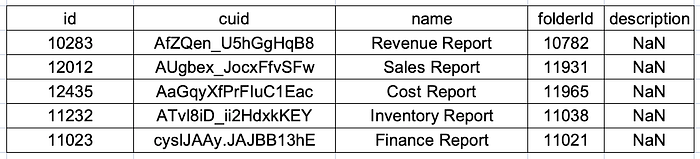
Part 3: Document Details Extraction
If you need additional details such as the document’s path, last updated time, scheduling status, size, and refresh status, utilize the following function. This function fetches the specified details for each document in the df_documents DataFrame, providing a more comprehensive overview of each entry.
def get_document_detail(documentID, detail):
url = 'http://{}:6405/biprws/raylight/v1/documents/{}'.format(localhost, documentID)
res = requests.get(url, headers={
"Accept": "application/json",
"Content-Type": "application/json",
"X-SAP-LogonToken": logon_token
}).json()
return res['document'][detail]
def get_more_information_from_documents(df):
details = ['path', 'updated', 'scheduled', 'size', 'refreshOnOpen']
for detail in details:
df[detail] = [get_document_detail(id, detail) for id in df['id'].values]
return df
df_documents_more_info = get_more_information_from_documents(df_documents)Showcasing df_documents_more_info: